
はじめに:本記事の対象者は以下を想定しています。
検索エンジンのクローラーとインデックスを制御する方法には、「robots.txt」と「noindex」という2つの方法があります。
検索エンジンにナンバーを伝えるための指示である「robots.txt」と「noindex」は、検索エンジンを最適化するためのSEO対策において重要な役割を果たしています。
しかし、誤った使い方をしているケースや、上手く活用する事ができず、正しくSEO評価されていないサイトを非常に多く見かけます。
特にテクニカルSEOが重要であるDB型の大規模サイトなどでは、この使い分けなどを理解しておく事は非常に大切です。
そこで今回は、「robots.txt」と「noindex」の違いについてご紹介します。また、SEO対策における使い分けや注意点についても詳しく解説するので、ぜひ参考にしてください。

SEO対策のお悩み
を無料で相談する
Step1
ありがとうございます
弊社にご相談頂きまして
誠にありがとうございます。
クーミル株式会社では、
1つ1つのご相談を真剣に考え、
最適解をご提供出来るよう日々努めております。
可能な限り、即日ご返信を心掛けておりますが、
相談内容や、
営業日の関係で少々、
お待たせさせてしまうかも知れません…。
目次
- 1.「robots.txt」と「noindex」の違いとは?
- 1-1.「robots.txt」の役割と書き方
- 1-2.「noindex」の役割と書き方
- 2.「robots.txt」と「noindex」の使い分け
- 2-1.「robots.txt」を使うシーン
- 2-2.「noindex」を使うシーン
- 3.「robots.txt」と「noindex」の反映を確認する方法
- 3-1.「robots.txt」の確認方法
- 3-2.「noindex」の確認方法
- 4.「robots.txtのdisallow」と「noindex」の併用時の注意点
- 4-1.「noindex」の効果がなくなる可能性がある
- 4-2.インデックス情報の更新が遅れる
- 4-3.設定が複雑化し、設定ミスのリスクが高まる
- 5.「robots.txt」と「noindex」を併用する際の対策
- 5-1.「noindex」と「nofollow」を併用する
- 5-2.ディレクトリではなく個別に設定する
- 5-3.robots.txtはルートディレクトリに設置する
- 5-4.サイトマップを活用する
- 6.まとめ
1.「robots.txt」と「noindex」の違いとは?
robts.txtとnoindexの違いは簡単にお伝えすると以下の画像の通りです。

robots.txtとnoindexは、ともに検索エンジンの動作を指示するという点で共通しています。robots.txtとnoindexの主な違いは下記の通りです。
| 項目 | robots.txt | noindex |
|---|---|---|
| 動作・役割 | クローラーのアクセスを許可・拒否 | インデックス登録の許可・拒否 |
| 目的 | ・サイト内に類似ページがあり、正しくSEO評価がされていない時 ・低品質コンテンツであるが、削除したくない時 | ・クローラーバジェットの最適化 ・クローラーにアクセスして欲しくない |
| 影響範囲 | 全ての検索エンジン | 指定した検索エンジンのみ |
以下では、「robots.txt」と「noindex」それぞれの役割と書き方について詳しく解説します。
クーミルでは、SEOコンサルティングのみならず、実行支援まで一貫して対応可能です。Web制作会社だからこそできるテクニカルSEOにも対応可能となります。ぜひご相談くださいませ。
1-1.「robots.txt」の役割と書き方
robots.txtを使う大きな目的としては、クロールバジェットを最適化し、正しくページ評価をさせることです。
▼クローラーバジェットについて
Webサイトは無限にあるのに対して、Googleが行うクロールには能力の限界があります。
そのため、大規模サイトなどのWebサイトでは、すべてのページをクロールしてもらえないこともあります。
クロールが必要なページと不要なページを最適化する必要があります。
詳しくは、大規模なサイト所有者向けのクロール バジェット管理ガイドをご確認ください。
大規模サイト(ページ数:5000~)を超えるような場合に、テクニカルSEOとしてrobots.txtが使われることが多いです。大規模サイトの場合、重複ページやクローラーが巡回しなくても全く問題ないページなどがあります。
イメージ
- 物件情報、詳細の口コミ:口コミ一つ一つにURLが付番されているケース
これらのURLは文字数が少なく、クローラーが巡回されても、低品質ページと認められる可能性が高い
このようなページに対して適切にrobots.txtを設定していないと、「クロール済み-インデックス未登録ページ」のページが膨大に蓄積されてしまいます。
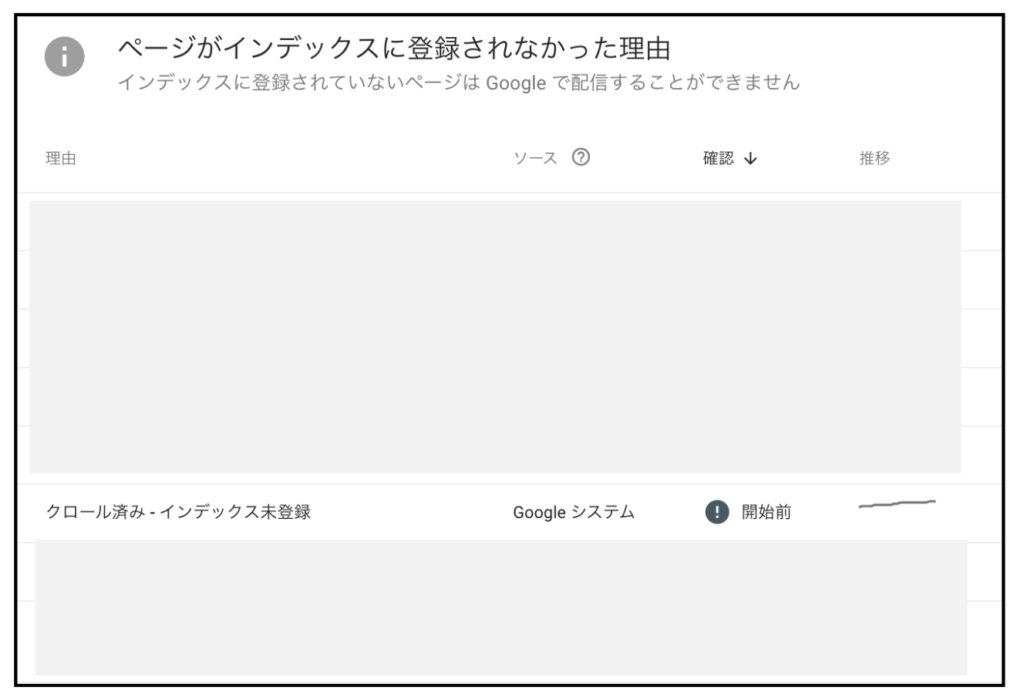
低品質ページが増えるだけでなく、上位表示化させたいページに対して、適切にクローラーが巡回しない恐れがあります。
その結果、SEO評価を正しく受けることが出来ず、中々上位表示できないケースがあります。
robots.txtを活用することで、最適化することが出来、正しくSEO評価を受けることが可能となります。
robots.txtの記述内容
| User-agent | クローラーの種類を指定する |
| Disallow | クローラーがアクセスできないページやディレクトリを指定する。 |
| Allow | クローラーがアクセスできるページやディレクトリを指定する。 |
WordPressでの設定方法

上記の画像のような形で、「このページのrobotsタグ」という項目が投稿ページの下部に表示されています。
上記の設定を変更することで、robots.txtを有効活用することが可能です。
注意点
テスト段階においてrobots.txtでサイト全体のクロールをブロックするのは避けましょう。ローカル環境を構築せずに、本番環境でサイトを構築する場合は、Basic認証を設定するか、もしくは全ページnoindexにすることを推奨します。
1-2.「noindex」の役割と書き方
noindexは、検索エンジンに特定のページがインデックスされないように検索エンジンに伝えるマークアップタグのことです。
noindexは、HTMLのmeta要素を使用して、検索エンジンに対して特定のページをインデックスしないように指示します。robots.txtとの違いは、インデックスをブロックしますが、クロールは実行されない点です。
robots.txtよりも細かい制御が可能です。
サイト内に粗悪なページや類似コンテンツが存在した場合、ページがクロールされると検索エンジンからの評価が下がり、検索順位に悪影響を及ぼすことが考えられます。
noindexを使用することで、検索結果に表示したくないページをインデックスから除外できるため、検索順位に悪影響を及ぼす心配がありません。
noindexを実装するには、下記の2つの方法があります。
noindexの設定方法
noindex metaタグをページのHTMLコードに入力する。
<meta name="robots" content="noindex">
WordPressで設定する場合
プラグインを活用して行う:「SEO SIMPLE PACK」をインストール・有効化
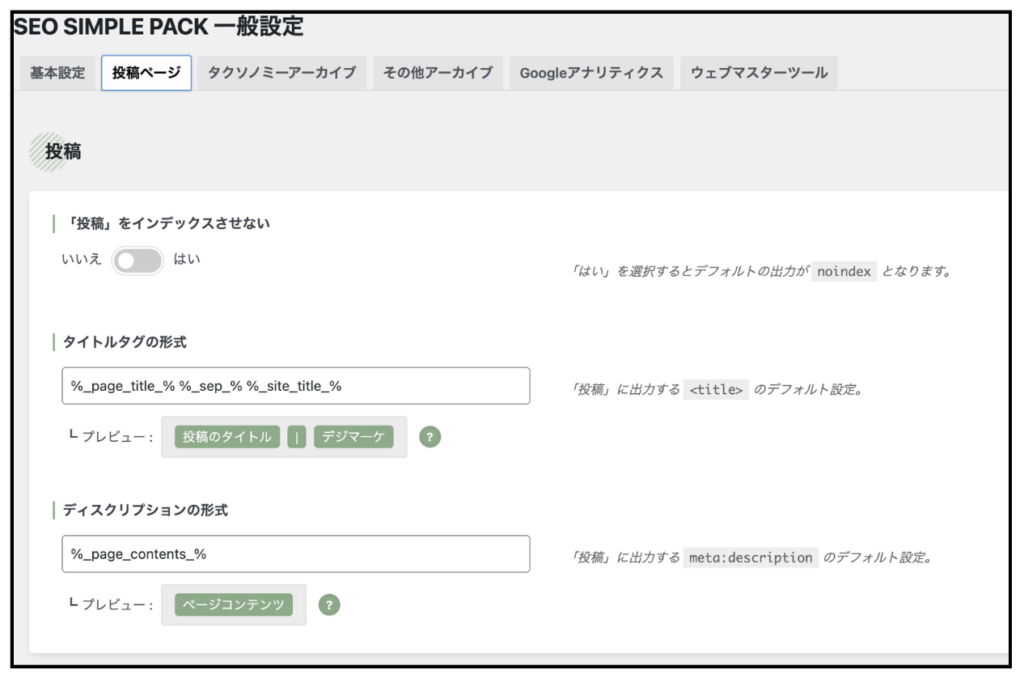
インデックスさせたくないページに対して、「インデックスさせない」設定を行う
上記の対応を行うことでnoindexタグを設置することが可能です。
2.「robots.txt」と「noindex」の使い分け
robots.txtは検索エンジンのクローラーにアクセス許可を与えるページを指定します。一方、noindexはインデックスから除外したいページを指定します。r
obots.txtとnoindexは、それぞれ異なる役割を持っていることが分かりました。
状況に応じて、robots.txtとnoindexを使い分けることが大切です。
ここでは、「robots.txt」と「noindex」の使い分けについて詳しく解説します。
2-1.「robots.txt」を使うシーン
2-2.「noindex」を使うシーン
noindexは、サイト評価をアップさせる施策というよりは、「サイト全体の評価を下げないための施策」といった意味合いが強いと言えるでしょう。
3.「robots.txt」と「noindex」の反映を確認する方法
robots.txtとnoindexを記述した後、反映されているか確認する方法は以下の通りです。
3-1.「robots.txt」の確認方法
robots.txtの確認方法は、以下の2つです。
- ブラウザで直接確認する方法
- Google Search Consoleを使う方法
ブラウザで直接確認する方法
ブラウザのアドレスバーに「[無効な URL を削除しました]」と入力し、Enterキーを押します。
robots.txtファイルが存在する場合は、内容が表示されます。
Google Search Consoleで確認する方法
Google Search Consoleの「URL検査」ツールにURLを入力、表示画面からrobots.txtの確認が可能です。
3-2.「noindex」の確認方法
noindexの確認方法は、robots.txtと以下の2つです。
- ページソースを確認する方法
- Google Search Consoleで確認する方法
ページソースを確認する方法
noindex設定をしたページを開く→右クリックで「ページのソースを表示」→comand+Fで「noindex」と検索

このような形、noindex設定「<meta name=”robots” content=”noindex”>」とされているか確認しましょう。
Google Search Consoleをで確認する方法
Google Search Consoleのページをクリック→「noindexタグによって除外されました」の項目を確認
4.「robots.txtのdisallow」と「noindex」の併用時の注意点
robots.txtとnoindexは、検索エンジン最適化のためのSEO対策において重要な役割を果たす要素です。
「robots.txtのdisallow」と「noindex」を併用することで、より詳細なアクセス制御とインデックス管理が可能になります。
しかし、併用することでサイトに悪影響を及ぼす可能性もあるため注意が必要です。
ここでは、「robots.txtのdisallow」と「noindex」を併用した際の注意点を詳しく解説します。
可能であれば、テクニカルSEOに対して知見がある制作会社やSEOコンサル会社に依頼することをお勧めいたします。
4-1.「noindex」の効果がなくなる可能性がある
robots.txtでクローラーのアクセスを拒否すると、クローラーはそのページにアクセスできません。
noindexでページをインデックス登録させたくない場合、robots.txtでブロックしていることが原因で、クローラーがページをクロールできずにnoindexの指示が伝わらない可能性があります。
これは、クローラーがページにアクセスできずに、noindexタグを読み取れないためです。
結果的に、ページがインデックスに残ってしまうことが考えられます。
意図しないページがインデックスから除外されてしまう場合もあるため注意が必要です。
対処法
robots.txtでブロックしていることで指示が伝わらない場合は、robots.txtで指定しているページの「robots.txtの指定」を解除してください。指定を解除することで、noindexをクローラーにインデックスさせることが可能です。
もし、robots.txtの指定を解除できない場合は、手間はかかりますが、Google Search Consoleの「削除」を使用してインデックス削除の申請もできます。ただし、Googleの検索結果上で削除した場合、適用されるのは6か月間程度です。
Googleの検索結果に、再度情報が表示される可能性があることを理解しておきましょう。
確実にインデックスを削除するためには、サーバー上からページ自体を削除するか、パスワード保護を施したアクセスをブロックする必要があります。
4-2.インデックス情報の更新が遅れる
noindex設定後にrobots.txtでクローラーのアクセスを許可した場合、インデックス情報の更新が遅れる可能性があります。
これは、検索エンジンがページの再クロールに時間を要するためです。
4-3.設定が複雑化し、設定ミスのリスクが高まる
robots.txtとnoindexを併用すると、設定が複雑化し、設定ミスのリスクが高まります。
基本的に、robots.txtファイルでブロックしている場合、クローラーはページをクロールすることはありません。ただし、外部サイトや内部リンクからリンクを貼られている場合は、リンクを通して該当ページがクロールされる場合があります。
robots.txtは、クローラーへのクロール指示に用いることが一般的で、Webサイト上の一般ユーザーのアクセスを制限するといった機能はありません。robots.txtを用いてクロールを拒否しても、URLが公開されている限り、誰でもアクセスできてしまいます。
特定のサイトコンテンツに一般ユーザーからのアクセスを制限したい場合は、Basic認証などのパスワードの保護を施す必要があります。または、サーバー自体から非表示にしたいページを削除してください。
5.「robots.txt」と「noindex」を併用する際の対策
robots.txtとnoindexを併用する場合は、以下の対策を講じることでリスクを軽減できます。
robots.txtとnoindex両方の機能が必要な場合は、慎重に設定を行いましょう。
5-1.「noindex」と「nofollow」を併用する
noindexとnofollowを併用することで、クローラーにページのインデックス登録を拒否できます。
また、他のページへのリンク情報も伝達しないようにできます。
5-2.ディレクトリではなく個別に設定する
robots.txtでディレクトリ全体へのアクセスを拒否するのではなく、個別に設定することで、意図しないページがインデックスから除外されることを防ぐことが可能です。
5-3.robots.txtはルートディレクトリに設置する
クローラーはサイト訪問の際、はじめにrobots.txtファイルを参照し、どのページをクロールすべきか、もしくは避けるべきかの指示を受け取り判断します。robots.txtファイルは、必ずサイトの最上位階層であるルートディレクトリに設置しましょう。
5-4.サイトマップを活用する
サイトマップを活用することで、検索エンジンにインデックスしてほしいページを明確に伝えることができます。
6.まとめ
「robots.txt」と「noindex」を適切に使用することは、SEO対策においても非常に重要なポイントです。
SEO・コンテンツマーケティングで売上を伸ばしたいのであれば、欠かせない施策と言えるでしょう。
「robots.txt」と「noindex」を適切に使用できれば、優先的に重要なコンテンツがクロールされて高い評価を受けインデックスされます。Web集客を成功に導くためにも、「robots.txt」と「noindex」それぞれの役割と違いを理解し、状況に応じて適切に使い分けることが重要です。
また、「robots.txt」と「noindex」を併用する場合は、注意点や対策をしっかり理解した上で実施するようにしましょう。
ぜひ本記事を参考にして、「robots.txt」と「noindex」を適切に使用して、Web集客を成功させてください。




















